今天给大家介绍一下关于前端相关PS操作之切图和合并sprite,首先给那些已经学习完HTML/CSS基础知识,想模仿做一个静态页面,但缺少对ps了解的新手同学,那么下面我们一起来看一下吧。
一、准备工作
切图前需要先对PS进行基本设置,记住一些快捷键能帮我们更快的工作。
工作区设置
通过窗口打开:信息、字符、图层、历史记录、选项。
信息面板:配合矩形选框可显示距离、鼠标定位坐标
字符面板:显示字体、字体大小、字体颜色、行高
历史记录:快速返回到历史状态
单位设置
信息调板设置:颜色RGB,标尺单位px
编辑——首选项——单位与标尺:单位px
快捷键
整体移动:空格+鼠标
整体缩放:ait+滚轮
取消:ctrl+D
返回上n步:ctrl+alt+Z
移动:V
文字:T
选框:M
吸管:I
切片:K
标尺:ctrl+R
新建参考线:alt+V+E(可直接设参数)
参考线:ctrl+;
拿到设计图,可以先分析页面的结构分布,判断设计图中公共样式部分,判断出图中需要切出单独保留的图片和需要拼接Scrpite图片。
二、切图
切图前先确定切图范围,并且隐藏掉图上的干扰信息(比如文字,不必要的小短线,图标什么的)。
1. Icon/Logo
这类图片常常尺寸不是很大,起指示作用,较少变更,背景往往为透明。切这种图片可以用这两种方法。
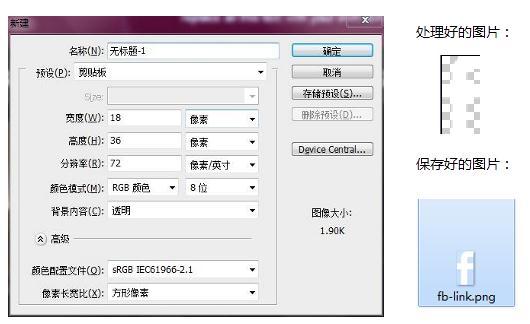
1.1新建psd另存对象
操作
移动工具选中——图层转化为智能对象——选框工具框选大致区域、ctrl+c、ctrl+n确定——ctrl+v——ctrl+alt+shift+s——PNG-24/8、命名save、关闭窗口
photoshop操作之前端PS操作切图和合并sprite
无需仔细框选图片边沿,也能非常准确的切取图片
一次只能处理一张图片,适用于图比较少的情况
对于由多个图层组成的icon,需要先全部选取并合并图层
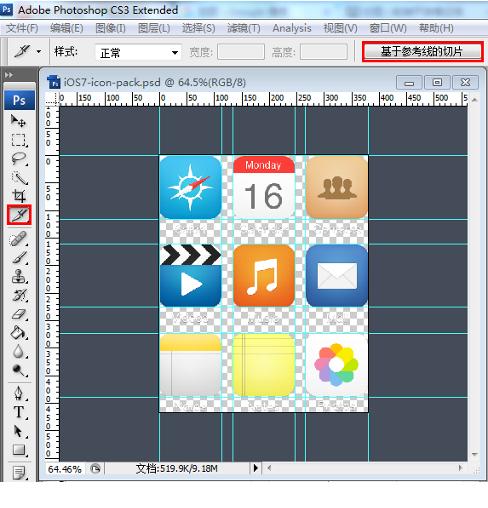
1.2 切片法
操作
切片工具K——选择相应位置切片——隐藏背景/文字——ctrl+alt+shift+s、切片选择工具(可单独选几个保存)、PNG-24/8保存——保存所有用户切片、文件位置,保存

photoshop操作之前端PS操作切图和合并sprite
可一次切完单页面上所有图片后一次性保存,当然保存图片格式是一致。
切片时适当放大图片,注意图片边缘。可提前设好准确的参考线。
对于比较规整的页面,可以利用【基于参考线自动切片】
photoshop操作之前端PS操作切图和合并sprite
1.3 保存
颜色单一,且【无】半透明效果opacity——存为PNG8
颜色单一,且【有】半透明效果opacity——存为PNG24
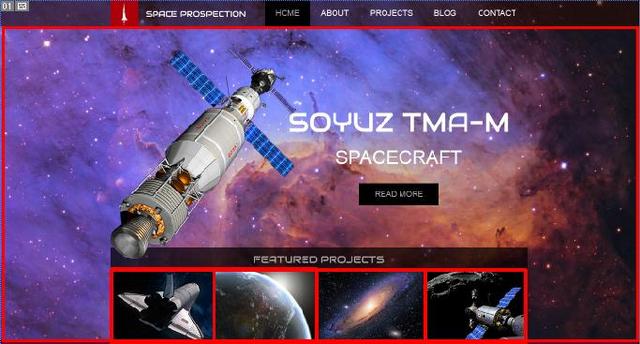
2. 内容/背景
设计中有些图片是表达具体内容,往往随着页面内容的更新而变更并且颜色会更丰富。(如下图红框所示)
photoshop操作之前端PS操作切图和合并sprite
2.1操作
覆盖图层隐藏——选框图片——alt+I、p裁剪——ctrl+alt+shift+s——JPEG、60——ctrl+alt+z还原
当然,这些图片往往需要存储的格式比较单一,可以直接全部切片,保存。
2.2存储
颜色丰富,无透明色——存为JPEG60/80
JPEG有损压缩,数值越高,图片质量越高
三、合并sprite
为了减少http请求数量,加速页面显示。我们可以将加载量较大,不随用户信息变化的多个小图片拼接成雪碧图。
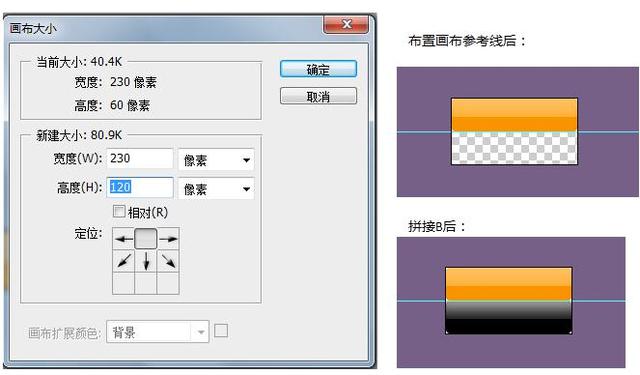
操作
选中A图层、转化为智能对象、选框工具框选区域、ctrl+c、ctrl+n、ctrl+v
——图像画布大小、定位、更新宽/高——放好交界参考线——选中B图层、转化为智能对象、选框工具框选区域、ctrl+c、回到新建窗口、ctrl+v
photoshop操作之前端PS操作切图和合并sprite
四、测距/获取颜色值
当然,除了以上。我们还有两个非常常用又非常简单的ps操作:测距和获取颜色值。写CSS一定会用到。
测距
矩形选框直接拉,在信息面板可见宽(w)高(H)
字体大小直接看字符面板
获取颜色值
吸管吸取相应位置,工具栏设置前景色点一下,即可得各种形式颜色数值
可多吸取几个位置,注意颜色数值是否有变化,确定有无渐变
如果您觉得本文的内容对您的学习有所帮助:
关键字:
IE下的有条件注释详细讲解