响应数据和结果视图
返回值分类
1.返回值是String
返回值类型是字符串的,会根据返回的字符串去寻找相对应的jsp页面
@Controller
@RequestMapping("/user")
public class UserController {
//返回值类型是String
@RequestMapping("/testString")
public String testString(Model model){
System.out.println("testString方法执行了");
//模拟从数据库中查询出User对象
User user = new User();
user.setAge(20);
user.setPassword("123");
user.setUsername("任我行");
//使用model把对象存起来
model.addAttribute("user",user);
return "success";
}
2.返回值是Void
默认请求路径是什么就会去寻找请求路径的jsp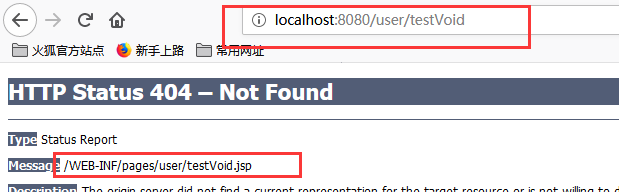
编写请求转发和重定向的程序和直接响应
@Controller
@RequestMapping("/user")
public class UserController {
//返回值类型是String
@RequestMapping("/testString")
public String testString(Model model){
System.out.println("testString方法执行了");
//模拟从数据库中查询出User对象
User user = new User();
user.setAge(20);
user.setPassword("123");
user.setUsername("任我行");
//使用model把对象存起来
model.addAttribute("user",user);
return "success";
}
//返回值类型是Void
//请求转发是一次请求:不用编写项目的名称
@RequestMapping("/testVoid")
public void testVoid(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("testVoid方法执行了");
//编写请求转发的程序
// request.getRequestDispatcher("/WEB-INF/pages/success.jsp").forward(request,response);//转发
//response.sendRedirect(request.getContextPath()+"/index.jsp");//重定向
//设置中文乱码
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
response.getWriter().print("hello,大笨蛋");
return;
}
}
返回值是ModelAndView对象(存JavaBean对象和跳转页面)
//返回值类型是ModelAndView
@RequestMapping("/testModelAndView")
public ModelAndView testModelAndView(){
ModelAndView mv = new ModelAndView();
System.out.println("testModelAndView执行了");
//模拟从数据库中�7��定单击事件
$(function(){
$("#btn").click(function(){
$.ajax({
//编写json格式,设置属性和值
//url:请求服务器的路径
url:"user/testAjax",
//contentType:发送内容给服务器是的编码类型
contentType:"application/json;charset=UTF-8",
//data:发送到服务器的数据
data:'{"username":"hehe","password":"123","age":"20"}',
//dataType预期服务器返回的类型
dataType:"json",
//tpye,请求方式
type:"post",
//success:请求成功后的回调函数
success:function(data){
//data服务器端响应的json的数据,进行解析
}
});
});
});
</script>
</head>
<body>
<br>
<button id="btn">发送ajax请求</button>
</body>
</html>
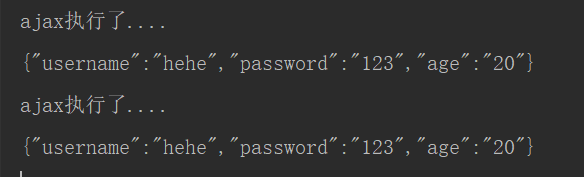
@RequestMapping("/testAjax")
public void testAjax(@RequestBody String body){
System.out.println("ajax执行了....");
System.out.println(body);
}
文件上传之上传原理分析
文件上传的必要前提
1.form表单的enctype取值必须是:multipart/form-data
2.method属性取值必须是Post
3.提供一个文件选择域
如果您觉得本文的内容对您的学习有所帮助:
关键字:
html